Tuning clustering
Carrot2 algorithms should produce reasonably good clusters out-of-the box for most inputs. If you'd like to fine-tune the quality or performance of clustering, this article discusses the possible approaches.
Desirable characteristics of input
The quality of clusters and their labels largely depends on the quality of documents provided on the input. Although there is no general rule for optimum document content, below are some tips worth considering.
-
Carrot2 is designed for small to medium collections of documents. Carrot2 algorithms perform in-memory clustering. For this reason, as a rule of thumb, Carrot2 should successfully deal with up to a thousand of documents, a few paragraphs each. For algorithms designed to process millions of documents, check out the Apache Mahout project or Carrot Search Lingo4G.
-
Provide a minimum of 100 documents. Carrot2 clustering algorithms work better with increasing amount of data. A hundred documents on input is probably the minimum for any statistical significance of features discovered by the algorithm. In general, an optimum number of documents would probably fall between 100 and a few thousands. More than that may cause problems due to in-memory processing.
-
Provide query-context snippets instead of entire documents. If the input documents are a result of some search query, provide contextual snippets related to that query (similar to what web search engines return), instead of full document content. Not only will this speed up processing, but should also guide the clustering algorithm to discover query-related spectrum of topics.
-
Minimize noise in the input documents. All kinds of noisy fragments in the input like truncated sentences, random alphanumerical strings or repeated boilerplate may decrease the quality of cluster labels. If you are extracting query context for clustering, retrieving complete sentences instead of truncated fragments should improve cluster labels even further.
Tuning parameters
The default settings that come with each algorithm are good for an average case. Each clustering algorithm comes with a number of parameters affecting its output and runtime characteristics. See the algorithm's reference page, such as Lingo parameters, for a list and description of the parameters.
You can easily adjust parameters in Java API. If you call the REST API from Java code, a robust way to override parameters is to use request model classes.
When using the REST API directly, an easy way to get the parameters JSON object is to use Carrot2 Workbench: set the desired values using the left-hand-side panel and then press the parameter export button to get the JSON with just the parameters that are different from defaults.
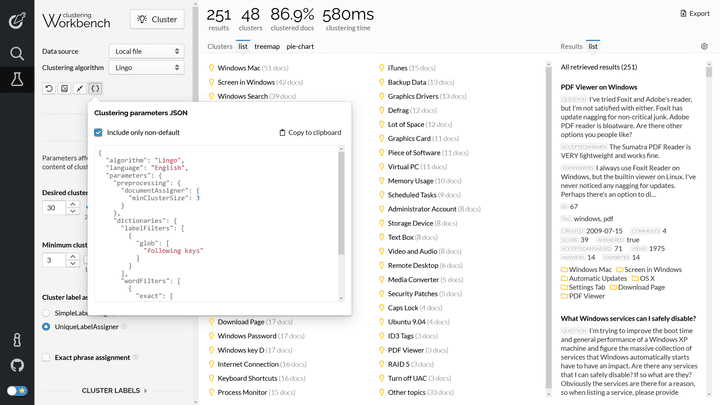
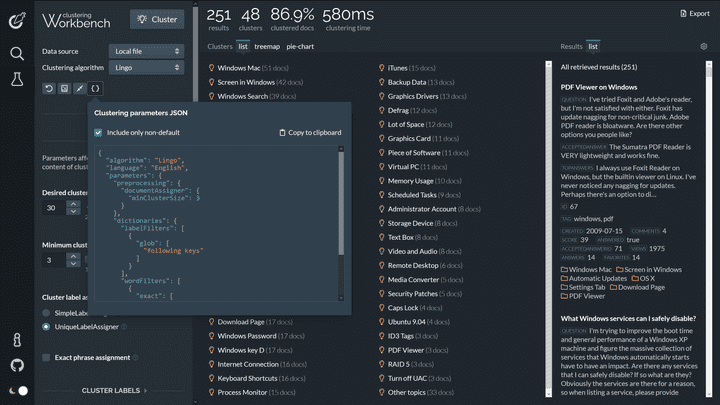
Exporting parameters JSON in Carrot2 Workbench.
Tuning language resources
In order to achieve good cluster labels and high clustering quality it is vital to adjust the default language resources so that they exclude any common terms, phrases and expressions specific to:
-
the selected language, including function words such as for or between (the default resources should contain a reasonable number of these already);
-
the domain of documents being clustered.
For example, if clustering documents from the medical domain, certain expressions and terms may be obvious and trivial to the domain. Forming clusters out of these wouldn't be of any value to the users. By excluding such expressions the algorithms are guided to look for other, perhaps more interesting alternative content.
Language resources can be adjusted in many ways. See the relevant bits of documentation in the Java API, the REST API and word and label filtering dictionary syntax.
Performance tuning
Carrot2 clustering algorithms have been designed to work really fast but the trade-off is that they store all the data structures in memory. The size of the Java virtual machine's heap will increase quickly with longer overall size of input text. Also, the more documents you put on input and the longer the documents are, the longer the clustering will take.
Below are a few generic guidelines on improving clustering performance.
Reduce size of input
In many cases clustering short document excerpts may work just as well or even better than full documents. Consider the possibility of replacing full content with:
- query-matching document fragments (such as search result snippets), if input documents are a result of some type of user-entered query,
- titles and abstracts of documents, if they are available,
- just the leading few sentences or paragraphs of each document.
Batch and merge smaller clustering runs
In many cases when the input collection of documents is too large to cluster as a whole, dividing the input into smaller batches (or sampling smaller batches from the input), then clustering separately and finally merging based on cluster label text gives very reasonable results.
The above approach works because cluster labels recurring in smaller batches are very likely to be significant for the entire collection. The downside is that very small clusters containing just a few documents are likely to be lost during this process.
Tune algorithm parameters
In many cases the default parameter settings for each algorithm may not be suitable for very large inputs. Below are some parameter customization suggestions you should consider. You will likely need to experiment a bit to adjust their values to match the size of your particular input.
STC, Bisecting k-Means
wordDfThreshold
Increase the minimum document frequency (minimum number of occurrences) of terms and phrases to a higher value. Something like 0.5% of the number of documents will typically work. For example, for a document collection of 5000 documents set the parameter to 25.
Lingo
wordDfThreshold, phraseDfThreshold
Increase the minimum document frequency (minimum number of occurrences) of terms and phrases to a higher value. Something like 0.5% of the number of documents will typically work. For example, for a document collection of 5000 documents set the parameter to 25.
factorizationQuality
For algorithm.matrixReducer.factorizationFactory implementations that support
this parameter, lower factorizationQuality. This will cause the
matrix factorization algorithm to perform fewer iterations and hence complete quicker.
Alternatively, you can set algorithm.matrixReducer.factorizationFactory
to an implementation of PartialSingularValueDecompositionFactory, which is
slightly faster than the other factorizations and does not have
any explicit factorizationQuality parameter.
maximumMatrixSize
Lower maximum matrix size in matrixBuilder. This will cause the matrix
factorization algorithm to complete quicker and use less memory. The tradeoff is that with
small matrix sizes, Lingo may not be able to discover smaller clusters.