REST API Basics
This article will walk you through the methods offered by the Carrot2 HTTP/REST service.
Carrot2 Document Clustering Server (DCS) exposes Carrot2 clustering as a stateless HTTP/REST service. The DCS contains:
-
HTTP REST service endpoints for document clustering, dynamic inspection of service components and an OpenAPI descriptor,
-
a search engine-like application for clustering data from public sources, such web search results or PubMed abstracts,
-
Clustering Workbench, a browser-based application for more advanced users wishing to cluster content from local files (Excel, CSV, JSON), Solr or Elasticsearch engines,
-
a few Java examples that make use of model classes and query the REST API,
-
built-in Jetty HTTP server,
-
this documentation.
In the examples below we will refer to the DCS and the REST service interchangeably, although the service application context can be separated and deployed on any other web application container, such as Apache Tomcat.
Installation and running
To install the Document Clustering Server:
-
Make sure you have Java 11 or later available in your system.
-
Download the latest Carrot2 release and extract the archive to a local folder.
-
Run the DCS:
$ cd dcs $ ./dcsBy default the DCS will bind to port 8080. To change the port number, use the
--portcommand line parameter.$ dcs --port 8080 09:47:32: DCS context initialized [algorithms: [Bisecting K-Means, Lingo, STC], templates: [frontend-default, lingo, stc, bkmeans]] 09:47:32: Service started on port 8080. -
Once started, the DCS is ready to accept requests:
-
http://localhost:8080/service/ – Carrot2 REST API,
- http://localhost:8080/service/openapi – OpenAPI documentation,
- http://localhost:8080/frontend/ – search engine application,
- http://localhost:8080/frontend/#/workbench – Carrot2 Clustering Workbench,
- http://localhost:8080/doc – this documentation.
-
API workflow
The document clustering service exposes two endpoints:
- /service/clustering
- Performs clustering of the documents provided in JSON format, returns clusters in JSON format. This endpoint is stateless, the result is fully determined by the contents of the request JSON.
- /service/list
- Returns the list of available algorithms, their supported languages and preconfigured request templates.
The simplest way to perform clustering is to invoke the
/service/cluster with a hardcoded algorithm and
language, such as Lingo and English. In a more
advanced scenario, you may want to first request the list of algorithms
and languages from /service/list.
Clustering
To cluster documents, send a POST request to the /service/cluster
endpoint containing a JSON object with the documents to cluster,
the clustering algorithm and language to use and, optionally, clustering
parameters to apply.
POST /service/cluster HTTP/1.1Host: localhost:8080
{
"algorithm": "Lingo",
"language": "English",
"parameters": {
"preprocessing": {
"documentAssigner": {
"exactPhraseAssignment": true
}
}
},
"documents": [
{ "title": "PDF Viewer on Windows" },
{ "title": "Firefox PDF plugin to view PDF in browser on Windows" },
{ "title": "Limit CPU usage for flash in Firefox?" }
]
}
An example Carrot2 REST API clustering request.
The JSON object passed as request body supports the following properties:
- algorithm
-
The algorithm to use to perform clustering, required. You can get the list of clustering algorithms available in the DCS from the service configuration endpoint.
- language
-
The language in which to perform clustering, required. You can get the list of languages supported by each clustering algorithm from the service configuration endpoint.
- documents
-
Documents to cluster, required.
Each element in the array represents one document. Each document is a JSON object with property names denoting field names and property values representing the text to cluster. Field values must be strings or arrays of strings.
You should limit input documents to just those fields that should be clustered.
- parameters
-
Values of algorithm-specific parameters, optional. See the reference page of a specific algorithm, such as Lingo parameters, for the list of parameters and the JSON structure they are arranged in.
The easiest way to tune parameter values is to use Carrot2 Workbench, where you can observe the results in real-time and get the parameter JSON ready to paste into your request.
To encapsulate the common parts of the request, you can use the request templates feature. Finally, the clustering endpoint supports a number of GET parameters described in the OpenAPI descriptor.
The response will contain a JSON object similar to the one shown below.
{
"clusters": [
{
"labels": [
"Firefox"
],
"documents": [
1,
2
],
"clusters": [],
"score": 0.17439038910197008
},
{
"labels": [
"Windows"
],
"documents": [
0,
1
],
"clusters": [],
"score": 0.2183744736336805
}
]
}The clusters property contains a potentially recursive hierarchy of document clusters, where each cluster has the following properties:
- labels
- Cluster description label or labels.
- documents
- An array of references to documents contained in the cluster. Each reference is a 0-based index of the document within the documents array provided in the clustering request.
- clusters
- An array of subclusters of this cluster. The array will be empty if the algorithm does not support hierarchical clustering or subclusters could not be created.
- score
- The cluster's quality score. The score is not normalized in any way but represents relative quality of each cluster within this request.
Simple example
To make a quick clustering test, create a file called clustering-request.json
with the following contents:
{
"language": "English",
"algorithm": "Lingo",
"documents": [
{ "title": "PDF Viewer on Windows" },
{ "title": "Firefox PDF plugin to view PDF in browser on Windows" },
{ "title": "Limit CPU usage for flash in Firefox?" }
]
}
We need to know the algorithm to be used for clustering and the language
in which our documents are written, so that an appropriate preprocessing
is applied to input text before clustering. In this example we will use
hardcoded values for the Lingo algorithm and the English
language.
Assuming the DCS is running in the background, the clustering service's
default endpoint is at http://localhost:8080/service/cluster.
We are ready to send the above JSON for clustering using a command-line tool, such as
curl:
curl -X POST --header "Content-Type: text/json" --data-binary @cluster-request.json "http://localhost:8080/service/cluster?indent"
Note the MIME type for JSON must be set to Content-Type: text/json.
The response contains puts documents 1 and 2
in the Firefox cluster and documents 0 and
1 in the Windows cluster. This illustrates the
fact that certain algorithms can assign the same document to multiple
clusters.
{
"clusters": [
{
"labels": [
"Firefox"
],
"documents": [
1,
2
],
"clusters": [],
"score": 0.17439038910197008
},
{
"labels": [
"Windows"
],
"documents": [
0,
1
],
"clusters": [],
"score": 0.2183744736336805
}
]
}Per-request dictionaries
This example will demonstrate how to override clustering algorithm parameters and provide per-request label exclusions.
First, make the following clustering request:
{
"algorithm": "Lingo",
"language": "English",
"documents": [
{ "title": "PDF Viewer configuration issue on Windows" },
{ "title": "Firefox plugin configuration issue on Windows" },
{ "title": "CPU usage for flash in Firefox" }
]
}
You will notice that the algorithm created two clusters: Configuration Issue on Windows and Firefox. Some users may perceive the former phrase as non-informative and may wish to re-run clustering with the phrase excluded from cluster labeling.
You can achieve this by providing the dictionaries parameter for the Lingo algorithm. The parameter specifies the label exclusions to apply to the specific clustering request.
The following request excludes from labelling all phrases containing the word issue and also the word configuration. See the Dictionaries page for a detailed description of dictionary types and entry syntax.
{
"algorithm": "Lingo",
"language": "English",
"parameters": { "dictionaries": { "labelFilters": [ { "glob": [ "* issue *", "configuration" ] } ] } }, "documents": [
{ "title": "PDF Viewer configuration issue on Windows" },
{ "title": "Firefox plugin configuration issue on Windows" },
{ "title": "CPU usage for flash in Firefox" }
]
}
With the extra label filters in place, the algorithm will create two clusters labeled Firefox and Windows.
Service configuration
To receive the list of available clustering algorithms and languages,
make a GET request to the /list endpoint.
GET /service/list HTTP/1.1
Host: localhost:8080
{
"algorithms" : {
"Bisecting K-Means" : [
"Arabic",
"English",
...
],
"Lingo" : [
...
],
"STC" : [
...
]
},
"templates" : {
"frontend-default": {
"algorithm" : "English",
"language" : "Lingo"
},
"lingo": { ... },
"stc": { ... },
"bkmeans": { ... }
}
}
Note that each algorithm has an associated list of languages it supports.
The templates block enumerates preconfigured
request templates .
Request and response Java models
While it is perfectly fine to assemble the request JSON by hand, the DCS distribution comes with data model Java classes that can be used to build request and parse responses. The example shown in the previous section can be expressed in Java code by the following snippet:
LingoClusteringAlgorithm algorithm = new LingoClusteringAlgorithm();
algorithm.preprocessing.phraseDfThreshold.set(1);
algorithm.preprocessing.wordDfThreshold.set(1);
ClusterRequest request = new ClusterRequest();
request.algorithm = LingoClusteringAlgorithm.NAME;
request.language = "English";
request.parameters = Attrs.extract(algorithm);
request.documents =
Stream.of("foo bar", "bar", "baz")
.map(
value -> {
ClusterRequest.Document doc = new ClusterRequest.Document();
doc.setField("field", value);
return doc;
})
.collect(Collectors.toList());The request can be then serialized into JSON using the Jackson library. The DCS Java examples contain a few command-line applications that make extensive use of these model classes, please refer to them for details.
Alternatively, the OpenAPI descriptor can be used to generate service binding code for Java and many other languages.
OpenAPI service descriptor
The DCS comes with an OpenAPI service specification descriptor, by default accessible at: http://localhost:8080/service/openapi/dcs.yaml This descriptor contains documentation and working examples for all service endpoints and parameters.
The DCS ships with three OpenAPI specification browsers:
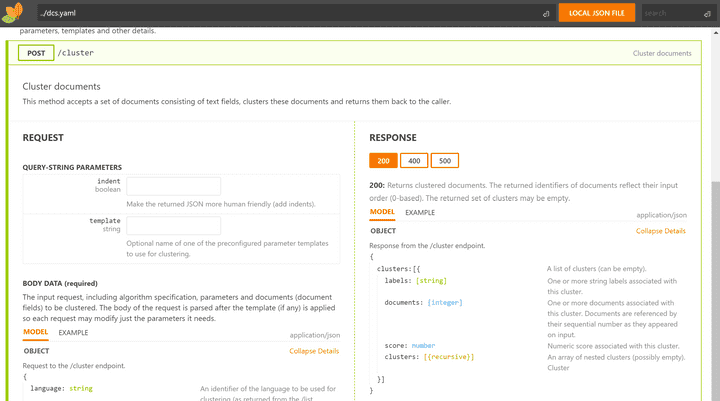
RapiDoc's representation of DCS's OpenAPI descriptor.